Реляционная система управления базами данных
Почти все продукты баз данных, созданные с конца 70-х годов, основаны на подходе, который называют реляционным (relational); более того, подавляющее большинство научных исследований в области баз данных в течение последних 25 лет проводилось (возможно, косвенно) в этом направлении. На самом деле, реляционный подход представляет собой основную тенденцию сегодняшнего рынка, и реляционная модель - единственная наиболее существенная разработка в истории развития баз данных. К.Дейт, Введение в системы баз данных.
Данную главу о проектировании реляционных баз данных мы начнем с определений основных понятий. Материал книги выстроен в этом плане несколько нестандартно. Обычно, изложение работы с базами данных начинается с теоретических основ. Мы же пошли от практической работы и начали с решения конкретных задач на языке SQL и разработки клиентских приложений. И теперь, когда имеется некоторый опыт работы с базами данных, мы подведем немного теории и определений. Стандартный подход плох тем, что у читателя или слушателя лекций сначала пухнет голова от теории и определений, в которых он начинает разбираться и понимать только после практической работы с базами данных. Важно также отметить, что теория баз данных сильно расходится с тем, что мы наблюдаем на практике. Итак, приступим. К.Дейт в своей классической книге "Введение в системы баз данных" дает следующее определение реляционной системы управления базами данных.
- Данные воспринимаются пользователем как таблицы (и никак иначе).
- В распоряжении пользователя имеются операторы, которые генерируют новые таблицы из старых.
Как уже было сказано, таблица состоит из столбцов и записей. На пересечении столбца и записи находится ячейка. Общих ячеек, как в системе Exell, быть не может. Каждый столбец имеет заданный типа данных, а также ограничения на допустимые значения и диапазон значений.
Одна из непосредственных задач СУБД (здесь и далее речь идет о реляционных СУБД, поэтому слово "реляционный" опускается) - осуществлять контроль целостности данных. Под целостностью данных подразумевается логическая непротиворечивость данных. Различают три понятия целостности:
- Целостность в отношении конкретной базы.
Такие данные, как возраст, рост, вес не могут быть отрицательными. IP-адрес имеет строго заданный формат - это четыре числа в диапазоне от 0 до 255, разделенных точкой, плюс дополнительные ограничения на использование 0, 255 и спецадресов. Большинство СУБД не предоставляют механизмов, в полной мере позволяющих контролировать данный тип целостности.
- Целостность сущностей.
В таблице, где хранятся записи об объектах, не может быть двух одинаковых объектов, а также не может быть неопределенных объектов, т.е. записей с неопределенным значением (NULL-значением) первичного ключа. СУБД не должна допускать записей с повторяющимися значениями первичного ключа или NULL-значением одного из компонентов первичного ключа. Данный тип целостности поддерживают все СУБД. Более подробно мы поговорим об этом понятии целостности ниже, при описании первичных ключей.
- Ссылочная целостность.
Как вы уже видели на примере системы гостевых книг(см. рисунок ниже) в главе "Язык SQL", одной записи в таблице гостевых книг может соответствовать несколько записей в таблице сообщений. Таблицы могут находиться во взаимосвязях один к одному, один ко многим и многие ко многим. Связи между таблицами осуществляются на основании внешних ключей. В таблице сообщений не может быть сообщения, принадлежащего к несуществующей гостевой книге, иначе говоря, любой записи в таблице сообщений должна найтись запись в таблице гостевых книг. СУБД должна предоставлять механизмы для контроля операций и соблюдения ссылочной целостности при выполнении операций INSERT, UPDATE и DELETE. К сожалению, не все СУБД имеют такие механизмы.
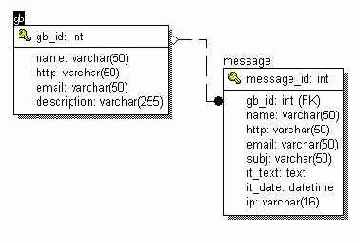
Система гостевых книг.
Рассмотрим более детально все три понятия целостности данных по порядку. К первому типу целостности относятся такие механизмы СУБД, как ограничение на диапазон допустимых значений, триггеры и транзакции. К сожалению, пока ни один из этих механизмов не поддерживается СУБД MySQL, поэтому, если ваши сайты будут базироваться на данной СУБД, то вам придется обождать до появления данных возможностей. Ограничения на значения должны появится уже в четвертой версии MySQL. При помощи ограничений на значения можно задать ограничение на формат адреса электронной почты.
email varchar(32) CHECK (email LIKE '%@%'),
Тем самым, запретив значения, которые не содержат знака '@'. Большинство же информационных систем применительно к веб-сайтам, будь то конференции, чаты, списки рассылки, имеют довольно простую структуру базы данных, обычно не превышающую 5-7 таблиц. В таких системах целостность данных не имеет критического значения. В случае ввода неправильного адреса электронной почты ничего катастрофического не произойдет, поэтому контроль за целостностью данных можно переложить на приложения, т.е. CGI-программы.
Механизм триггеров позволяет СУБД контролировать операции INSERT, UPDATE и DELETE на предмет допустимости этих операций. Например, таким образом, вы можете ограничить число публикуемых сообщений в день от одного пользователя или запретить вводить сообщения, длиной более 255 символов, лицам, незаполнившим поля email и http.
И наконец, последний механизм транзакций, о котором вам необходимо иметь представление, позволяет контролировать выполнение блоков SQL-запросов. Транзакция представляет собой набор SQL-запросов, и СУБД гарантирует, что либо все эти запросы будут выполнены, либо же ни один из них не будет выполнен. Транзакции могут применятся при вставке, изменении и удалении данных в нескольких таблицах. Например, вам необходимо в системе гостевых книг объединить две гостевые книги в одну. Для этого необходимо изменить идентификатор гостевой книги gb_id в таблице сообщений, удалить одну запись из таблицы гостевых книг и, возможно, модифицировать запись о первой гостевой книге. И мы должны быть полностью уверены в том, что либо эти операции пройдут успешно, либо же не будет выполнена ни одна из них.
Далее мы рассмотрим целостность сущностей. Как уже было сказано выше, целостность сущностей базируется на первичном ключе. Мы дадим определение первичного ключа и рассмотрим ряд примеров таблицы и методов выбора первичных ключей.
Первичный ключ - это столбец или группа столбцов в одной таблице таких, что не может существовать двух записей с одинаковым значением этого столбца или группы столбцов, причем для случая группы столбцов никакое подмножество столбцов не является уникальным.
Можно выделить принципиально различающиеся три случая:
- в таблице отсутствует первичный ключ;
- простой первичный ключ, т.е. состоящий из одного столбца;
- составной первичный ключ, т.е. состоящий из нескольких столбцов.
Рассмотрим первый случай, когда в таблице может и не быть первичного ключа, как, например, в таблице hit в системе анализа посетителей веб-сайта. В этой таблице просто нет столбцов, которые могли бы образовать первичный ключ. В таблице, чисто теоретически, с очень малой долей вероятности могут быть полностью одинаковые строки. Один пользователь может запустить на своем компьютере два броузера и открыть в них страницу нашего сайта. Из-за того, что ни операционная система, ни протокол TCP\IP не работают в реальном времени, и в них имеются задержки по времени, есть вероятность того, что открытие в этих броузерах нашей страницы произойдет одновременно. Соответственно, поскольку броузеры одни и те же, работают на одном компьютере, то программа counter внесет в таблицу hit две одинаковые строчки. Также небольшое пояснение, что CGI-программа counter может быть запущена одновременно несколько раз, и что сервер тоже работает не в реальном времени, поэтому и есть вероятность появления одинаковых строк.
В таблице hit нет необходимости различать записи, т.е. иметь первичный ключ. Если бы такая необходимость была, то можно было бы добавить в таблицу счетчик записей. В СУБД MYSQL это делается следующим образом:
CREATE TABLE hit( hit_id int(10) unsigned NOT NULL auto_increment, ... )
При вставке новой записи hit_id будет увеличиваться на единицу, тем самым мы получим возможность различать записи внутри таблицы. В системе гостевых книг первичными ключами являются поля gb_id в таблице гостевых книг и message_id в таблице сообщений. На практике чаще всего встречается именно такой способ назначения и использования первичных ключей. В таблицах системы гостевых книг первичные ключи служат для идентификации записей и установления отношения один ко многим. В классической теории для соблюдения целостности сущностей необходимо назначать первичным ключом столбец или группу столбцов, которые однозначно идентифицируют объект. Но в реальности, зачастую, таких столбцов может и не быть. Ни в таблице сообщений, ни в таблице гостевых книг нет осмысленной группы столбцов, которую бы можно было назначить первичным ключом. В данном случае, первичным ключом можно только сделать все столбцы таблицы сообщений, но, в этом случае, мы осложняем себе жизнь при выборе конкретного сообщения. В запросе SELECT * FROM message WHERE name='name' AND email='email' AND... придется перечислить совпадение для каждого столбца. Такая выборка будет происходить медленно, т.к. нужно затратить время, чтобы выполнить сравнение для каждого столбца. Гораздо удобнее ввести счетчик, тогда запрос будет выглядеть значительно проще: SELECT * FROM message WHERE id='id'.
Если же у вас в таблице имеется все же столбец или несколько столбцов, однозначно идентифицирующих объект, то их бесспорно стоит назначить первичным ключом. Например, у вас база данных по автомобилям, в этом случае, первичным ключом будет номер автомобиля. Не стоит пугаться того, что номер автомобиля представляется символьной строкой. Когда вы назначаете столбец или группу столбцов первичным ключом, по ним автоматически создается индекс. Индекс представляет собой хеш-таблицу, т.е. таблицу из двух колонок: в первой колонке в отсортированном порядке идут значения первичного ключа, а во второй колонке - указатель на то место, где лежит полная запись таблицы. Поскольку первая колонка отсортирована, то операции поиска по такой таблице происходят на порядок быстрее, чем если бы индекса не было. Для всех полей таблицы, которые участвуют в предложении WHERE SQL-запросов, надо обязательно создавать индексы. Однако, учтите, что индекс ускоряет поиск только в случае, если его значения слабо повторяются. Одним словом, если вы сделаете индекс по полю "пол", то никакого ускорения не получится, т.к. половина хеш-таблицы будет состоять из одних записей, а половина из других.
В MySQL индекс создается следующей командой:
CREATE [UNIQUE] INDEX index_name ON tablename (column1, column2, ...)
Составной первичный ключ может быть в таблице по персоналиям, где серия и номер паспорта представлены в отдельных колонках. В этом случае эти две колонки будут образовывать составной первичный ключ.
Внешний ключ - это столбец или группа столбцов в одной таблице R1, совпадающих по типу данных с первичным ключом в таблице R2, и каждому значению этого столбца или группы столбцов в таблице R1 обязательно должно найтись совпадающее с ним значение в таблице R2.
В нашем примере системы гостевых книг внешним ключом в таблице сообщений является поле gb_id, которое ссылается на поле gb_id в таблице гостевых книг. Оба этих столбца имеют одинаковый тип - int. В данном случае, внешний ключ состоит из одного столбца и именуется простым внешним ключом. В случае, если бы внешний ключ состоял из нескольких столбцов, он назывался бы составным. Обратите внимание, в случае составного внешнего ключа определение требует, чтобы типы столбцов совпадали. Определение внешнего ключа также говорит, что в таблице сообщений не может существовать записей, не относящихся ни к одной гостевой книге. Хотя обратное может быть, т.е. могут быть гостевые книги, не содержащие ни одного сообщения.
Давайте теперь рассмотрим, а что будет при попытке вставить сообщение с полем gb_id, не совпадающим ни с одной записью из таблице гостевых книг, или же удалить запись из таблицы гостевых книг. Здесь действует третий тип целостности, называемый ссылочной целостностью. СУБД должна контролировать операции INSERT, UPDATE и DELETE так, чтобы данные не оказались в подвешенном (противоречивом) состоянии. Для этих целей существуют два механизма. Один из них был уже нами поверхностно рассмотрен - это механизм триггеров. Второй механизм позволяет задать правила для связей по внешним ключам. СУБД предоставляют возможность либо ограничить, т.е. отвергнуть некорректные операции, либо же произвести каскадные изменения, т.е. при удалении записи из таблицы гостевых книг будут удалены все соответствующие ей по внешнему ключу записи из таблицы сообщений.
Далее мы рассмотрим типы отношений между таблицами:
- Отношение один ко многим
- Отношение многие ко многим
- Отношение один к одному
Отношение один ко многим мы уже детально рассмотрели на примере системы гостевых книг. Данного типа отношения реализуются при помощи внешнего ключа в одной таблице, который ссылается на первичный ключ другой таблицы.
Рассмотрим пример базы данных системы конференций. На конференцию авторами докладов подаются статьи. У каждой статьи может быть несколько авторов. У каждого автора может быть несколько статей. Подобного рода отношения называются многие ко многим и реализуются при помощи дополнительной таблицы с двумя внешними ключами, которые образуют первичный ключ, см. рисунок.
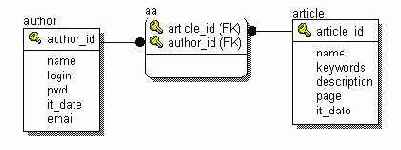
Вы видите таблицу авторов, которая относится к таблице aa (сокращение от authorarticle), как один ко многим. Это означает, что для одной записи в таблице авторов может быть несколько записей в таблице aa. Аналогичным образом и таблица статей относится к таблице aa, как один ко многим. А между таблицами авторов и статей реализуется отношение многие ко многим.
Теперь поговорим об отношениях один к одному. Вообще говоря, в некоторой литературе можно встретить утверждения, что подобного рода отношения есть аномалия, и что если у вас такое отношение между таблицами получилось, то, скорее всего, их лучше объединить в одну таблицу. На самом деле, это далеко не так, и мы сейчас это продемонстрируем. Итак, реализация отношения один к одному - это когда первичный ключ одной таблицы ссылается на первичный ключ другой. Такого рода отношение встречается значительно реже. Вот пример из нашей практики.
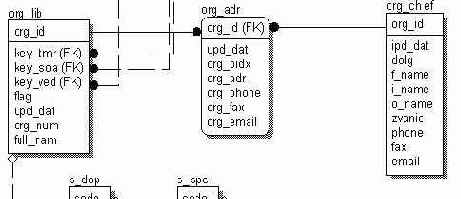
На рисунке изображен фрагмент базы данных, где отображены три таблицы: организаций, адресов организаций и руководителей организаций. Таблица организаций содержит название организации, описание ее функций, различные коды и т.д. Таблица адресов содержит данные исключительно об адресе. А таблица руководителей - о персоналиях, занимающих руководящие посты. Отношение между этим таблицами один к одному, т.к. организация может быть зарегистрирована строго по одному адресу и иметь одного руководителя. Поясним, почему нельзя объединить эти таблицы. Каждая из этих таблиц описывает свои объекты, атрибуты которых совершенно не связанны, т.е. звание руководителя никак не связано с улицей, где находится организация. В свою очередь, таблица организаций имеет отношение один ко многим со своими подразделениями, тоже можно сказать и про таблицу руководителей, которая находится в отношении один ко многим с подчиненными руководителя. Если объединить все три таблицы в одну, то получится путаница. Вы получите, что адрес организации состоит в отношении один ко многим с подчиненными руководителя, т.е. данные сольются без всякого смысла. Немаловажен и тот критерий, что работать с этими данными станет неудобно, и запросы будут выполняться медленнее.
Следующий классический пример отношения один к одному, т.е. связи двух таблиц по первичным ключам - это реализация подтипа данных. Допустим, вы делаете базу данных для магазина, торгующего автомобилями. У вас будет таблица с общими характеристиками автомобиля, например: цвет, стоимость, дата выпуска и тип (иномарка или отечественная). При описании реального проекта характеристик будет значительно больше. А теперь представьте, что поскольку машины могут быть отечественного производства и иномарки, то у машин отечественного производства есть свои параметры, которых нет у иномарок, например, гарантия завода изготовителя. В то же время и у иномарок есть свои параметры, которых нет у отечественных машин, например, из какой страны импортирована, пошлина, размещение руля (слева или справа). Здесь приходит на выручку отношение один к одному, т.е. мы реализуем своего рода подтипы, см. рисунок.
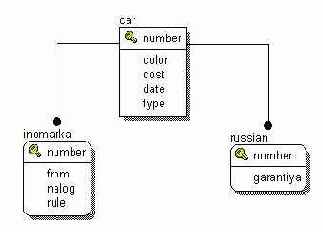
Любой записи в таблице car в зависимости от значения поля type соответствует запись либо в таблице inomarka, либо в таблице russian.
|
|